When it comes to projects, there are as many questions to answer as there are project teams, but “Where are we?” is by far the most popular. The key to understanding a project is to make regular measurements—both quantitative and qualitative—and display the measurements publicly. When project managers display these measurements as part of the project status, teams are able to adjust their work and proceed more successfully.
I like to call these measurements a “project dashboard.” You may not be able to show all the project measurements in one small area, such as one piece of paper, but taken together, the project measurements display your velocity, distance, consumption, and location—much as a car dashboard does.
Use Multi-dimension Measurements
It’s easy to measure some facets of a project, such as the project start date, the current date, and the desired release date and say, “We’re X percent of the way along,” because the project team has used that percentage of time. But if all you measure is the schedule, you’re almost guaranteed not to meet the desired deadline.
I like to measure a project along at least four out of six dimensions. I think of this as a project pyramid. (See Figure 1.)
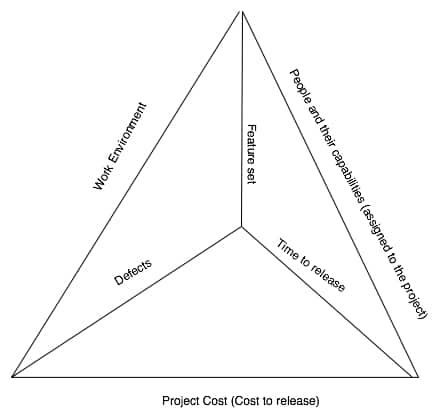
Figure 1: Project pyramid
The outside of the pyramid represents the constraints under which management has approved and funded the project. These project constraints are the work environment, the people and their capabilities, and the proposed project cost. I call them constraints because senior management tends to fix these attributes early in the project, and they tend to be difficult to change. Cost is the most likely to change, but in my experience it changes only when it becomes clear that the team can’t meet the desired deadline.
The project requirements are what your customers care about. (And yes, if you work in an IT group, it is likely that your customers are the same people who constrained the project’s cost, people, and environment.) Your customers care about what you’re going to deliver (the feature set), when they’ll receive it (time to release, the schedule), and how good that stuff is (defects). If you measure all sides of the pyramid, you will see a truer picture of your project than if you measure only one thing, such as schedule or defects, the two most common measurements I see.
Why Not Measure Earned Value?
So why not measure earned value? Earned value (taking credit for what you’ve been able to create in a specific amount of time) was developed to manage the tradeoff between measuring just the schedule and measuring what’s been accomplished. Earned value makes sense for products that can be created in self-contained pieces. You create a piece and measure how long it took and how much it cost (in people and time) to create that piece.
But for many software projects, it’s extremely difficult to calculate earned value. That’s because all parts of a software project are interdependent. Even if you implement feature by feature, which is as independently organized as you can make a software project, when you work on a new feature, you may have to return to completed work and change it. When you change completed work, it’s harder to determine the true earned value. Did you lose value because you changed something? Or, did you build on already-earned value? I have not worked on any project where it was possible to calculate earned value. In my experience, earned value is too often a fuzzy measurement for software projects.
Measure Project Completion
By using several measurements around the project pyramid, you can measure project completion. Project completion is a function of how accurate your original estimate was and how much progress you’ve made. But measuring only the schedule progress is not good enough. The only accurate way to measure progress for a software project is to measure how many features the project team has completed, how good those features are, and how many features are left to implement.
I once assessed a project in an organization where the developers had met every single date in the project schedules, but the testers were consistently late. Seems suspicious, doesn’t it? The developers hadn’t actually met any milestones at all—they checked in stubs and fixed the code when the testers reported defects. But because the project managers only looked at the dates—and never measured anything but the dates—the developers could say they had met the deadlines—without actually meeting them.
The only accurate way to measure progress for a software project is to measure how many features the project team has completed, how good those features are, and how many features are left to implement. As shown in the velocity chart in Figure 2, the number of features grew over the course of the project. The project team started with fifty features but released sixty-five features. If the team hadn’t tracked their progress including the number of features, they would not have been able to explain to their management why things took “so long.”

Figure 2: A velocity chart can be used to track schedule progress .
If I’m not implementing by feature, I like to use progress toward release criteria as a project completion measurement. Table 1 is an example of how I use release criteria to track project completion—or the lack thereof:
| Criterion | Status | Status | Status | Status |
| Performance of Scenario 1 under 10 seconds | 5/1, build 57: Performance < 30 seconds | 5/8, build 70: Performance < 15 seconds | 5/15, build 78: Performance < 12 seconds | 5/22, build 85: Performance < 8 seconds |
| Number of defects found decreasing for at least 4 weeks | 5/1, build 57:22 defects found, same as last week | 5/8, build 70: 15 defects found | 5/15, build 78: 5 defects found | 5/22, build 85: 2 defects found |
Table 1: Use release criteria to track project completion.
Release criteria are a late-in-the-project measurement. Even if you start assessing release criteria progress at the beginning of a project, most often, the release criteria data are available close to the end of the project.
No matter what lifecycle model you’ve selected for your project, to determine how good your initial estimate was, you can use Estimation Quality Factor (EQF), originally described by Tom DeMarco in Controlling Software Projects. At periodic intervals during the project, the project team answers the question “When do you think we’ll be done?” Each data point is the consensus agreement on when the project team believes the project will be finished. At the end of the project, draw a line backward from the release date to the beginning of the project. The area between the line you drew and the when-will-we-be-finished line is how far off your estimation was. This is a great technique for people to use as feedback on their individual estimates. But even if you don’t use it for feedback, it’s a great technique for the project manager to see what’s going on.

Figure 3: Example EQF for a project
Figure 3 is a chart of an EQF for a project that was originally supposed to be nine months long. For the first couple of months, when the project manager asked when people thought they’d finish, they said “September 1.” And for a couple of months, they were optimistic, thinking that they might finish early. But during the fifth month, team members realized they didn’t know enough about some of the requirements. What they discovered changed the architecture and pushed out the date. For the next few months, they still weren’t sure of the date. They realized in the last three months of the project that, because of the changing architecture, they were encountering many defects they hadn’t anticipated. So, evaluating EQF, a qualitative metric, was helpful to the project manager and the project team as a check against the progress charts.
Schedule estimates are just guesses, so anything you can do to show and then explain why your schedule varies from the initial plan will be helpful to anyone who wants to know “where are we?”
Collect a Variety of Project Measurements
Project completion measurements may be all your managers want to see, but if you’re a project manager or a technical lead on a project team, I’m sure you’d like some early warning signs that the schedule may not be accurate. To keep my finger on the pulse of a project, I monitor several measurements:
- Schedule estimates and actuals, aside from EQF
- When people (with the appropriate capabilities) are assigned to the project versus when they are needed
- Requirements changes throughout the project
- Fault feedback ratio throughout the project
- Cost to fix a defect throughout the project
- Defect find/close/remaining open rates throughout the project
Measure the Schedule When It’s All You’ve Got
I don’t use just Gantt charts to measure a schedule. Instead, I look at when the project team expected to meet a particular milestone and when they actually met that milestone. If the project team starts the project late (no matter what the first milestone is), that project is not going to meet the desired end date. Time lost is never going to be regained. Figure 4 shows what a comparison of schedule estimates and reality looks like.

Figure 4: Schedule Estimates vs. Actuals
This project is a modified waterfall lifecycle (the next phase can start without the previous phase being complete), but there are no iterations. Notice that the project started a full month late. When the project manager posted this chart, he also said this to senior management, “Don’t expect us to pull in the schedule by a month. We started late; we can’t make up the time.” To the project team he said, “I’d like you to work as intensely as you can, without working overtime and getting tired. We don’t have time for you to make mistakes. Do the best job as quickly as you can, and we’ll keep tracking where we are.”
See When Qualified People Actually Work on the Project
Too many projects start starved of resources. This can happen if some of the people are still working on a previous project, if people are yanked off partway through the project, or if your project is competing with several others for people’s time. The problem with starving a project is that no matter how hard people work when they are working on the project, they can’t make progress if they are assigned elsewhere or are attempting to multi-task on several projects. Figure 5 shows a project where the total number of planned person-months (666) was 75 percent of the actual person-months (878). Unfortunately, the team’s output was about 66 percent of the desired result.

Figure 5 : Tracking People’s Actual Assignment to the project
For more expense (about 1.3 times the original planned cost), the team delivered fewer features (0.3 times the original feature set). You might be asking why the project team would deliver less than planned for more cost? This project used a staged delivery lifecycle, where requirements, analysis, and architecture were timeboxed. The project team could obtain a good idea about the requirements and their effect on the architecture, but not know all the requirements in detail or know the implications of those requirements on the architecture. The original plan was to spend the first two months obtaining a good idea and the next two months performing an initial iteration to make sure the rest of the project would succeed. In order to be successful, the project plan required all the people planned in those first four months to perform all the initial investigation and iteration work. Since the people were not available and the end date was non-negotiable, the project team needed more people to prototype and iterate in parallel.
As people prototyped and iterated, they found mistakes—work that had not been completed in the initial timeboxing and iteration. Team members decided they would rather release a product that worked a little rather than release a product that had all the features, most of which didn’t work.
This chart supplied the project manager with opportunities throughout the project—and when planning for the next project—to explain to senior management the problem of starving a project.
If you ever start your projects starved of people who are capable of performing at 100 percent, this figure can help explain the consequences of that decision.
Determine the Rate of Change on Your Project
You may be working with people who are uncomfortable with velocity charts. Or, they may not believe the impact that some changes have on requirements. In that case, you can use a requirements change chart. (See Figure 6.)

Figure 6: Requirements Changes by Week
In this case, I was the project manager. I had a simple criterion for deciding if the requirements change was major or minor. A minor change affected one module, and a major change required changes to more than one module. To make this decision, I used the principle that “interface changes between modules tend to create defects.”
In this chart there are lots of small changes—something most of us expect on projects. But we also encountered some major requirements changes late in the project (Week 22). When I saw these requirements changes, I was able to explain to senior management that either the project would be later than we expected or the number of defects would rise. But with these changes, it was clear that the original date and the original feature set with the small number of expected defects was not possible.
See if the Developers Are Making Progress or Spinning Their Wheels
Once the project team is writing code, you can measure the fault feedback ratio (FFR). The FFR is the number of bad fixes to the total number of fixes. In my experience an FFR of 10 percent or more says that the developers are having trouble making progress.

Figure 7: Fault Feedback Ratio compared to number of Defects Closed
I like to measure the FFR on a weekly basis. I use FFR as data to initiate a discussion with the developers and testers. If I see a week where the FFR is high, I first check to see how many total problems were fixed that week. If only four problems were fixed and one was a bad fix, the developers and testers are probably OK. But if I see twenty defects fixed and five of them were bad fixes (25 percent), it’s more likely that somebody or a few somebodies are having trouble. In Figure 7, notice that the FFR starts to get high around Week 6 and stays over 10 percent until Week 13. Once the project team hit the second week of high FFR, the project manager instituted peer review on all fixes. That helped, but there was a delay between the start of peer review and the reduction of FFR back to numbers where the fixes didn’t interfere with progress.
To identify trouble areas, I first ask the developers if they are running into trouble with their fixes. I generally phrase the question this way: “When you fix something here, does a problem pop up over there?” I’ll ask other questions, all leading to asking the developers if they need any resources to fix this problem altogether. If I hear that the developers want to redesign a module, we discuss the issues for that redesign.
My next question is for the testers: “Are you able to define all the conditions that create this problem?” I start with those questions to see if the developers are fixing one piece of the problem at a time, or if the testers understand the system sufficiently to test thoroughly enough.
Measure How Much It Costs You to Find and Fix Problems
One key measure is how long it takes the project team to find and fix problems. You’ve probably seen “industry standard numbers” that look something like this:
| Phase/Cost | Requirements | Design | Code | Test | Post-release |
| 1 | 10 | 100 | 1 ,000 | 10 ,000 |
The idea here is that it costs you one unit to fix a problem in the requirements phase, ten units to fix a problem in design, one hundred units in code, 1,000 units in test, and 10,000 units in post-release. We normally think of units as dollars or some other form of currency.
I’ve measured cost to fix a defect, and the numbers I find are different. Table 2 shows costs from a couple of projects:
| Project Phase/Cost | Requirements | Design | Code | Test | Post-release |
| Project 1 (reactive for defects) | Not measured | Not measured | 0.5 person-day | 1 person-day | 18 person-days |
| Project 2 (proactive for defects) | 0.25 person-day | 0.25 person-day | 0.5 person-day | 0.5 person-day | 8 person-days |
Table 2: Measured Cost to Fix a Defect for Two Projects
Remember, it’s not just the cost per defect; it’s the cost per defect times the total number of defects. If you’re not looking at the overall cost, you can’t know where to spend your time. Based on cost to fix a defect from previous projects, you might decide to be proactive and use inspections of key project documents, test-driven development, or pair-programming for the more challenging defects. Or you might decide to monitor cost to fix a defect and take a more reactive response, such as peer review of fixes or inspection of all code.
If you haven’t performed any proactive defect-finding activities, the cost to find a defect is fairly small. But the cost to fix can be high, and the overall cost to fix all the defects is very large. If you have been proactive using techniques such as test-driven development, pair-programming, inspections, or peer reviews, the cost to find a defect can be higher—because you’ve already looked for defects. But the cost to fix a defect tends to be lower when a project team has been proactive in trying to find defects early. And the overall number of defects is lower, lowering your total cost to fix defects for a particular release.
I monitor cost to find and fix so I can see if the developers or testers are surprised by what’s in the code base. I have a couple of rules of thumb, assuming the developers have not been proactively looking for defects:
- The longer it takes developers to fix a problem, the more likely it is that the developers are afraid of touching parts of the system or that the developers don’t understand parts of the system.
- The longer it takes the testers to find problems, the less they know about the product or the less they know about multiple techniques to test the product.
The longer a defect takes to fix, the more careful we’ll have to be when deciding what to fix just before release.
Understand if the Developers and the Testers are Making Progress with Defects
Almost everyone measures defect trends. I’ve seen some intricate defect trend charts, but my favorite chart shows just three things: number of new defects found per week, number of closed defects per week, and the number of remaining open defects per week. (See Figure 8.) I specifically do not chart defects by priority. I find that the project team and senior management become too willing to play the promotion/demotion game when I chart defects by priority. And the developers have to read through all the defects, even if they are supposedly a lower priority. So, I just count all the defects.
I count the number of remaining open defects so I can see when the close rate passes the find rate, enough so that the number of remaining open defects starts to decrease. I look for the knee of that remaining open defects curve, knowing that as the slope of the remaining number of open defects goes negative, the risk of release lessens.

Figure 8 : Defect Trends over a Project
Display Qualitative Data
It would be easy if all the project data could be displayed on trend charts. But you need a different kind of chart, especially when you’re trying to explain the status of something. I’ve used progress charts like the one in Table 3 when trying to explain the progress of algorithm development, performance scenarios, and testing.
| Area/Module/ Feature | Last Test Date | State | Next Planned Test |
| Module A | 1/12, Build 37 | Blocked. See Ann for details. | Build 42 |
| Module B | 1/13, Build 40 | Passed all regression tests. | Recheck with Build 42 |
| Module C | 1/12, Build 38 | Passed all regression tests. Exploratory testing ongoing. | Ongoing Checking |
| Module D | 1/13, Build 39 | Vijay and Dan working together on regression tests. Major problems. | Build 41 |
| Module E | 1/13, Build 40 | Passed all regression tests. All fixes verified. No more effort until final cycle. | Final Build |
| Overall Status | As of 1/13, 4 p.m. | Approximately half done with planned system testing. | Projected Last Build: 57 |
Table 3 : Test Progress Chart
Displaying Data
I try to be consistent in my charts. Red is bad; green is good. Up is bad; down is good. Bad and good are very judgmental words, especially when applied to data. After all, data just is. But you may not be able to explain your data to everyone all the time. In that case, it’s helpful if people know how to read your charts. Tufte’s The Visual Display of Quantitative Information is a great resource, especially when your charts will be read and interpreted by other people.
In Data We Trust
Without data, you’re just another person with just another opinion. And while your opinion might be good, it’s not the same as having data. When you measure around your project pyramid, you’re gathering data that not only will explain where you are in this project but also data that will help you plan for the next project.
StickyNotes
References
- Rothman, Johanna. “Pragmatic Project Management Workshop.” 1999-2005.
- Grady, Robert. Practical Software Metrics for Project Management and Process Improvement. Englewood Cliffs, NJ, Prentice Hall, 1992.
- Rothman, Johanna. “Release Criteria: Is This Software Done?” STQE, March/April 2002.
- DeMarco, Tom. Controlling Software Projects: Management, Measurement and Estimation. Prentice Hall, 1982.
- Rothman, Johanna. “What Does it Cost to Fix a Defect?” stickyminds.com, February 7, 2002.
- Rothman, Johanna. “By the Dashboard Light.” stickyminds.com, July 9, 2004.
- Tufte, Edward, R. The Visual Display of Quantitative Information, Cheshire, CT, Graphics Press, 2001.
© 2006 Johanna Rothman. Originally published in Better Software, January 2006, pp 22-28.
Like this article? See the other articles. Or, look at my workshops, so you can see how to use advice like this where you work.
Pingback: Release Planning and Schedule Monitoring : Myth or Real | Managing Software Development
Pingback: Quantitative management, transparency and trust | SDTimes
Pingback: Managers Manage Ambiguity |